徐昊教授和Fausto Giunchiglia教授联合指导的2020级博士研究生宋瑞同学的论文Measuring and Mitigating Language Model Biases in Abusive Language Detection 近日被 Information Processing & Management(IPM)杂志接收。Information Processing & Management是Elsevier出版社旗下的中科院一区TOP期刊(CCF-B),SCI IF(2022)= 7.466。
宋瑞本科就读于澳门人威尼斯官方软件学院,2018年保送到计算机科学与技术学院,进入徐昊老师HAI(Human-Centered AI)实验室读研,2020年于澳门人威尼斯官方攻读博士学位。本篇论文的通讯作者为徐昊教授,其他作者包括Fausto Giunchiglia院士,澳门人威尼斯官方的博士研究生石立达同学等。
论文题目:Measuring and Mitigating Language Model Biases in Abusive Language Detection
第一作者:宋瑞
指导教师:徐昊、Fausto Giunchiglia
收录期刊:Information Processing & Management(IPM)
期刊级别:中科院一区,CCF B
论文概述:
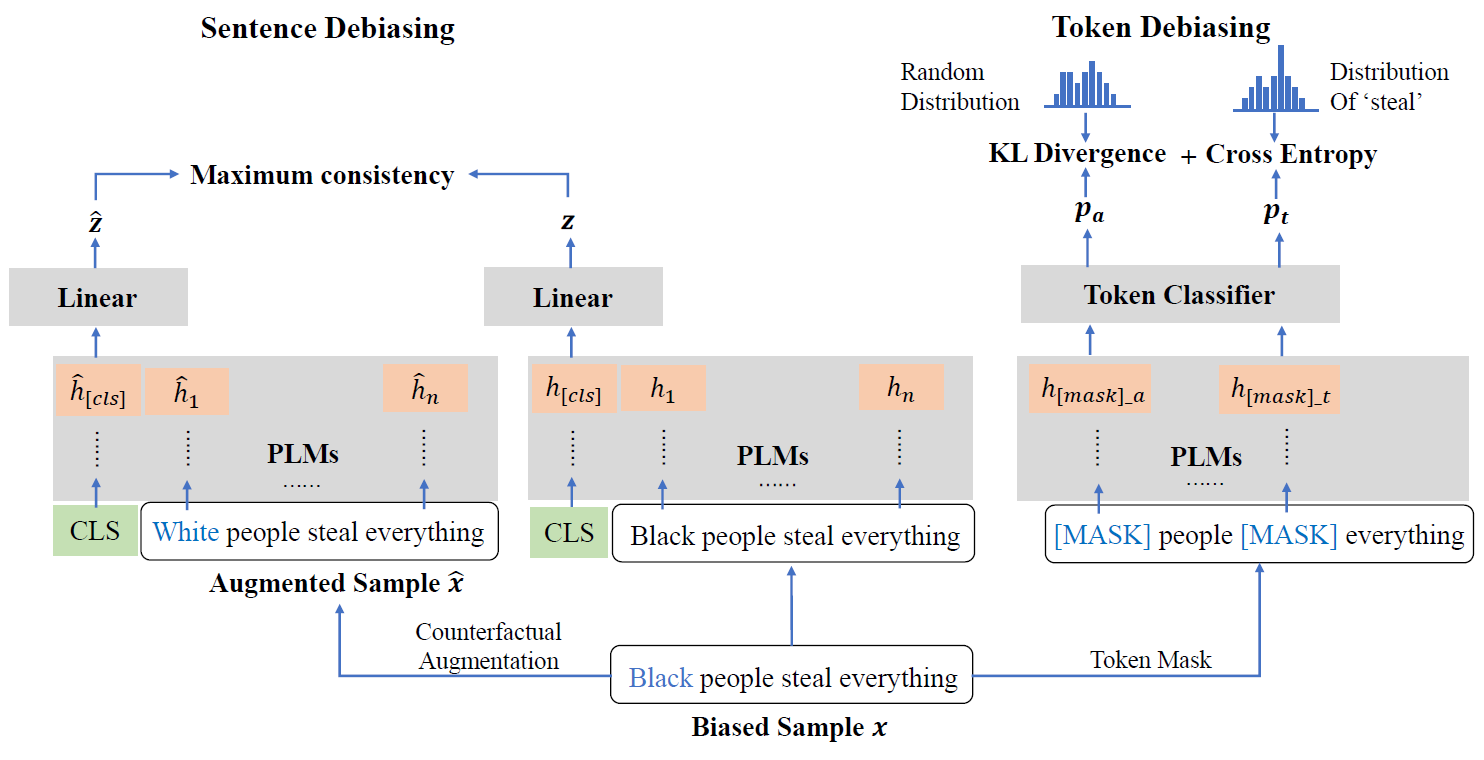
随着大规模预训练语言模型的兴起,基于预训练语言模型的分类逐渐成为辱骂语言自动检测的范式。然而,语言模型中固有的刻板印象对辱骂语言检测的影响仍然未知,尽管这可能进一步加强对少数弱势群体(妇女、儿童、移民等)的偏见,导致模型对包含上述群体的样本做出错误决策。为此,在本文中,我们使用多个指标来衡量语言模型中偏见的存在,并分析这些固有偏见对自动辱骂语言检测的影响。在此定量分析的基础上,我们提出了令牌去偏和句子去偏两种不同的去偏策略,在不降低分类性能的前提下,降低语言模型在辱骂语言检测中的偏见。具体来说,对于令牌去偏策略,我们通过随机概率估计来减少语言模型对特定群体的受保护属性词的依赖。在句子去偏策略中,我们利用反事实替换获得去偏样本,并利用原始数据与增强样本之间的一致性正则化消除语言模型句子层面的偏差。实验结果证实,我们的方法不仅可以降低语言模型在辱骂语言检测任务中的偏差,而且可以有效地提高辱骂语言检测的性能。